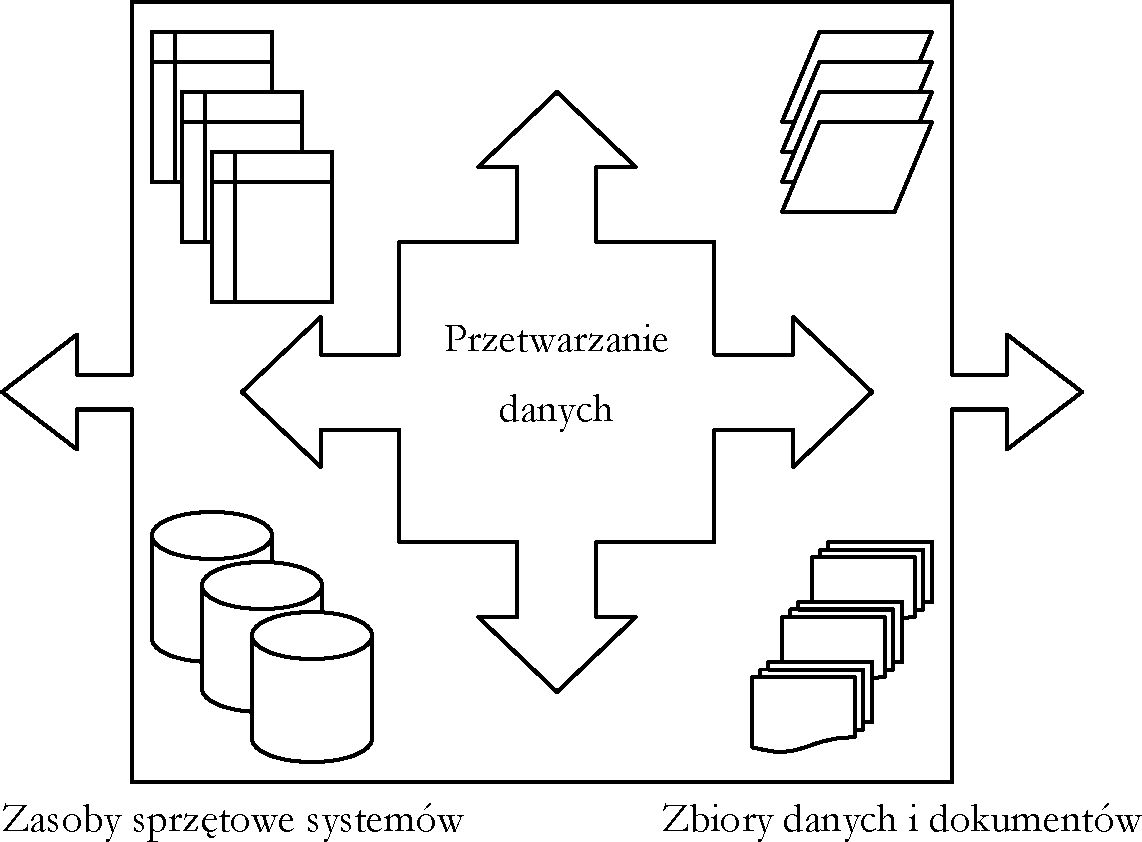
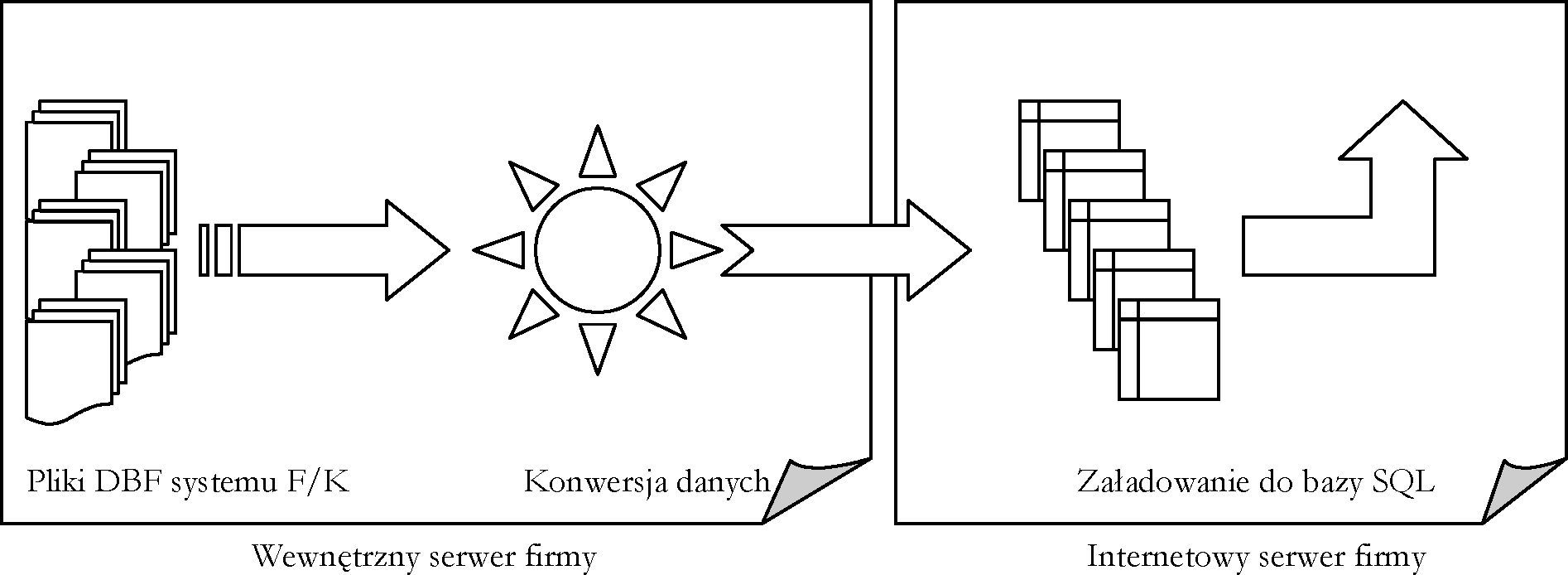
W trakcie realizacji projektu, w celu uatrakcyjnienia prezentowanych informacji, skonstruowano mechanizm przechowywania dodatkowych danych o towarach. Ma to na celu dostarczanie aktualnych danych technicznych oraz funkcjonalnych przeglądającym ofertę internautom. Prezentowane wyniki wyszukiwania towarów uzupełniono o odnośniki wywołujące dodatkowe okno z prezentowanymi informacjami. Obecnie trwają prace nad budową i udostępnieniem formularzy do rejestrowania tych informacji.
Z założenia będą one wykorzystywane przez określone działy firmy do aktualizowania tych informacji oraz dostępne jedynie z wewnątrz firmy. Informacje te obejmować będą swoim zakresem dane szczegółowe o towarze, odnośniki do dodatkowych informacji na stronach producentów sprzętu a także miniaturowe zdjęcia towaru. Po kliknięciu na miniaturowej fotografii produktu, system załaduje w osobnym oknie normalnej wielkości fotografię, rysunek, schemat a nawet film z przygotowaną prezentacją. Poniższy listing prezentuje kod realizujący wygenerowanie okienka i wyświetlenie tych informacji.
Skrypt PHP obsługuje stronę, która wyświetla szczegóły towaru pobrane z bazy danych. W pierwszej kolejności ładowane są pliki konfiguracyjne, takie jak inc/db.inc i inc/meta.inc, a także biblioteka phpDB.inc, która umożliwia połączenie z bazą danych. Następnie sprawdzana jest obecność JavaScriptu w przeglądarce użytkownika na podstawie zmiennej HTTP_USER_AGENT. Jeśli w agencie użytkownika znajduje się słowo „oziłła” (co jest błędem), ustawiany jest warunek jestjava na TRUE.
Kolejny etap to sprawdzenie, czy w systemie istnieje plik /tmp/emarket.tmp, który wskazuje na to, czy baza danych jest w trakcie ładowania. Jeżeli plik nie istnieje, skrypt wykonuje zapytanie do bazy danych w celu pobrania informacji o towarze, posługując się indeksem podanym w zapytaniu. Jeśli indeks nie zostanie dostarczony, wyświetlana jest informacja, że nie podano, czego szukać.
Po nawiązaniu połączenia z bazą danych za pomocą klasy phpDBO, wykonywane jest zapytanie SQL, które ma na celu pobranie szczegółowych informacji o towarze. Wynik zapytania jest przechowywany w zmiennej $resułt. Jeśli dane zostały znalezione, skrypt generuje tabelę HTML z informacjami o towarze, w tym nazwą, tytułem, opisem, linkami i innymi szczegółami.
Na końcu skrypt sprawdza, czy połączenie z bazą danych zostało poprawnie zakończone, a po zakończeniu przetwarzania zamykane są połączenie oraz pamięć, a użytkownik otrzymuje komunikat o zakończeniu operacji lub o tym, że baza danych jest aktualizowana.
Skrypt PHP, który został przedstawiony, jest częścią systemu zarządzania bazą danych towarów w sklepie internetowym lub systemie e-commerce. Jego przydatność można omówić w kontekście kilku kluczowych aspektów.
Pierwszym istotnym elementem jest obsługa dynamicznego wyświetlania szczegółów towaru. Skrypt pobiera dane o produkcie z bazy danych na podstawie unikalnego identyfikatora (indeksu) przekazanego przez użytkownika. Dzięki temu umożliwia wyświetlanie dokładnych informacji o towarze w czasie rzeczywistym. To jest niezwykle ważne w e-commerce, ponieważ pozwala na bieżąco prezentować aktualne dane o produktach, takie jak nazwa, opis, cena czy dostępność.
Drugim istotnym elementem jest sprawdzanie, czy strona jest w trakcie aktualizacji bazy danych. Jeśli tak, użytkownik otrzymuje komunikat informujący o konieczności odczekania, co pomaga uniknąć sytuacji, w których użytkownicy próbują uzyskać dostęp do danych w czasie, gdy są one zmieniane lub aktualizowane. To zapobiega występowaniu błędów lub niepełnych danych na stronie.
Dodatkowo, skrypt analizuje, czy przeglądarka użytkownika wspiera JavaScript, co może wpływać na dalszą interakcję z witryną. Jeśli JavaScript jest dostępny, użytkownik może zamknąć okno za pomocą skryptu, co zapewnia lepsze doświadczenie użytkownika, gdy strona jest zintegrowana z dynamicznymi elementami.
Skrypt ma także zabezpieczenia, które sprawdzają, czy parametr indeks został przekazany. Jeśli nie, użytkownik zostaje poinformowany, że musi podać, czego szuka, co zapobiega wyświetlaniu błędnych danych. Jest to element podstawowej walidacji danych wejściowych, co jest kluczowe w każdym systemie webowym, aby uniknąć wstrzykiwania nieprawidłowych danych do systemu.
Chociaż skrypt pełni wiele istotnych funkcji, jego przydatność mogłaby zostać jeszcze bardziej zwiększona poprzez poprawienie kilku kwestii. Na przykład, w kodzie znajdują się błędy, takie jak literówki (np. „incłude” zamiast „include”), które mogą prowadzić do problemów w jego działaniu. Warto także poprawić obsługę błędów, aby użytkownicy otrzymywali bardziej szczegółowe komunikaty, jeśli coś pójdzie nie tak.
Skrypt jest przydatny w kontekście wyświetlania szczegółowych informacji o towarze w sklepach internetowych, a także w zapewnianiu użytkownikom aktualnych danych, zabezpieczając jednocześnie system przed błędami podczas aktualizacji bazy danych. Jednak wymaga on poprawy pod względem jakości kodu i obsługi błędów.