Systemy zarządzania treścią zazwyczaj oparte są na bazach danych oraz na językach skryptowych po stronie serwera. Najczęściej spotykanym zestawem jest baza danych MySQL i język skryptowy PHP. Dane są oddzielone od szablonu strony i przechowywane w bazie danych. Aplikacje działające na serwerze pobierają dane i wyświetlają je w wyznaczonych uprzednio miejscach na stronie.
Warstwy
W systemach CMS nastąpiło oddzielenie warstwy prezentacji treści od warstwy aplikacji. Pierwsza z tych warstw jest tym, co widzą użytkownicy – naszą stronę internetową, która jest efektem naszej pracy. Druga z nich to warstwa, w której tworzymy nasz projekt, czyli warstwę, w której pracują osoby zarządzające stroną.
Strona internetowa, którą widzą goście i zalogowani użytkownicy to tzw. strona frontowa (ang. front end). W jej skład wchodzą: menu, zawartość, reklamy, różne funkcje, np. logowania użytkownika. Natomiast warstwą administracyjną strony jest zaplecze (ang. back end). Można w niej konfigurować oraz konserwować nasz portal, czyścić oraz tworzyć statystyki lub przygotowywać zawartość. Część tej warstwy znajduje się pod innym adresem URL (ang. Uniform Resource Locator) niż strona WWW.
Logowanie do panelu administracyjnego
Wstęp do panelu administracyjnego jest chroniony. Zarządzać systemem mogą tylko użytkownicy, którzy posiadają konto i odpowiednie uprawnienia – głównego administratora, administratora lub operatora.
Podczas logowania system sprawdza:
- czy logujący się ma prawo wstępu na zaplecze (ang. Access right),
- jakim poziomem uprawnień dysponuje, jakie może wykonywać zadania (ang. Access level).
Tę procedurę nazywa się często uwierzytelnieniem, autoryzacją, autentykacją czy rejestracją. Ale nie są to terminy równoznaczne. Uwierzytelnienie lub autentykacja to sprawdzenie, czy użytkownik jest tym, za kogo się podaje. Autoryzacja, to sprawdzenie, do czego użytkownik ma prawo. Natomiast rejestracja oznacza zakładanie konta użytkownika.
Prawa dostępu
Mówiąc o zarządzaniu myślimy o administracji istniejącymi zasobami. W CMS każdy użytkownik otrzymuje swój status, do którego przypisane są różne prawa dostępu. Wśród użytkowników wyróżniamy[1]:
- Zwykli użytkownicy (zarejestrowani i niezarejestrowani)
- Autorzy – autorzy mają prawo przesyłać materiały do wyznaczonych sekcji i kategorii artykułów oraz edytować swoje materiały.
- Redaktorzy – mają prawo dodawać i redagować artykuły w wyznaczonych sekcjach i kategoriach oraz edytować (redagować) artykuły wszystkich innych autorów.
- Wydawcy – mają prawo dodawać artykuły w każdej sekcji witryny, edytować (redagować) artykuły wszystkich innych autorów oraz dodatkowo decydować o opublikowaniu bądź zakończeniu publikacji każdego artykułu.
- Operatorzy – najniżsi rangą w grupie administratorów prawa do zarządzania artykułami i zarządzania pozycjami menu witryny. Nie mogą dodawać użytkowników ani modyfikować ich kont, nie mogą instalować składników systemu, nie mają na zapleczu dostępu do komponentów i modułów.
- Administratorzy – mogą prawie wszystko, z wyjątkiem spraw zastrzeżonych tylko dla głównego administratora. A więc nie mogą dokonywać zmian w konfiguracji, nie mogą instalować szablonów, języków. Ponadto nie mogą rozsyłać korespondencji seryjnej do użytkowników.
- Główny administrator – odpowiada za całą witrynę. Jest jedynym, który ma dostęp do wszystkich funkcji zaplecza oraz jedynym, który ma prawo konfigurować witrynę, instalować szablony i pliki językowe, tworzyć dodatkowe konta głównych administratorów. Konto głównego administratora zakładane jest podczas instalacji Joomla!.
Powyższy podział jest stosowany w Joomli!, lecz podobne rozwiązania występują w innych systemach CMS. Strona WWW wyświetla różną zawartość lub udostępnia strefę administracyjną w zależności od uprawnień użytkownika.
Szablony
Są to wizualne formaty edycyjne, w których umieszcza się w zawartość. Szablon określa rozmiar, kolor i krój czcionki, podział strony, odstępy między obiektami, czyli wszystko to, co odpowiada za wygląd strony. Dobry szablon powinien zapewnić administratorom i projektantom witryn[2]:
- swobodę decyzji o wyświetlaniu lewej i prawej kolumny,
- ukrywanie lewej i prawej kolumny, gdy nie ma w nich żadnych modułów,
- łatwą wymianę elementów identyfikacyjnych – logo, treści, stopki,
- wybór j ednego z kilku wariantów kolorystycznych.
Szablon można zaprojektować samodzielnie, poszukać darmowych wzorów w Internecie, zakupić gotowy projekt lub zlecić profesjonalnej firmie opracowanie go, gdyż wykonanie własnego szablonu wymaga znajomości HTML[3] oraz CSS[4].
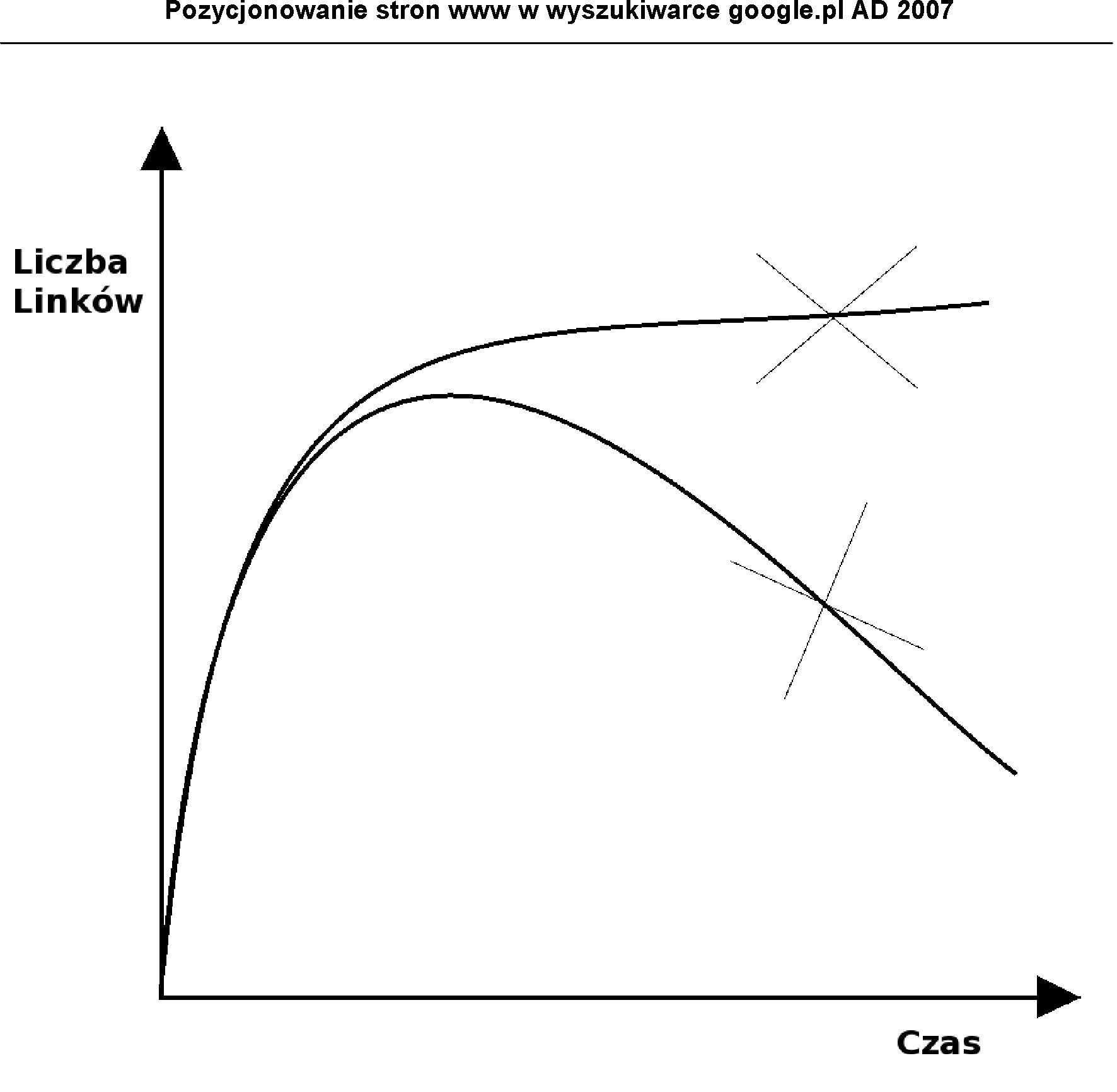
Typowym wzorcem rozmieszczenia treści na stronach CMS jest struktura portalu opartego na 3-kolumnowym układzie (rys.1). Jednak układ ten nie jest w żaden sposób ograniczony i można go w dowolny sposób modyfikować.
Rysunek 1. Struktura portalu tworzonego w Joomla! źródło: [Polskie Centrum Joomla!
| NAGŁÓWEK:logo, nazwa, logo, menu główne, menu narzędziowe, wyszukiwarka, ścieżka powrotu |
| LEWA KOLUMNA
menu główne lokalne użytkownika logowane i inne. |
MODUŁ |
MODUŁ |
PRAWA KOLUMNA |
| Tytuł st |
rony |
| GŁÓWNA TREŚĆ |
MODUŁ |
| MODUŁ |
| MODUŁ |
STOPKA: noty prawne, adresy, powtórzenie menu głównego
Trzypoziomowa struktura treści
Joomla! oraz inne systemy CMS obsługują różne typy zawartości takie jak: tekst, obraz, muzyka. Aby jednak dodać jakikolwiek artykuł, trzeba stworzyć przynajmniej jedną sekcję, a w niej kategorię[5] (rys.2).
Pozycje – są to podstawowe, pojedyncze elementy treści: tekst artykułu, odnośnik do strony WWW, adres e-mail, obraz w galerii, produkt w katalogu, itp.
Kategorie – to kolekcje, zbiory pozycji zgrupowanych ze względu na jakieś kryterium tj. temat, rodzaj, typ; w kategorie porządkowane są artykuły oraz informacje gromadzone w komponentach.
Sekcje i komponenty – zawierają kolekcje kategorii artykułów (sekcje) i innych materiałów (komponenty), są to kontenery, w których grupuje się kategorie.
Rysunek 2. Struktura organizacji zawartości publikowanej w Joomla! źródło: [Graf H., „Joomla! System zarządzania treścią.”, Helion, Gliwice 2007]
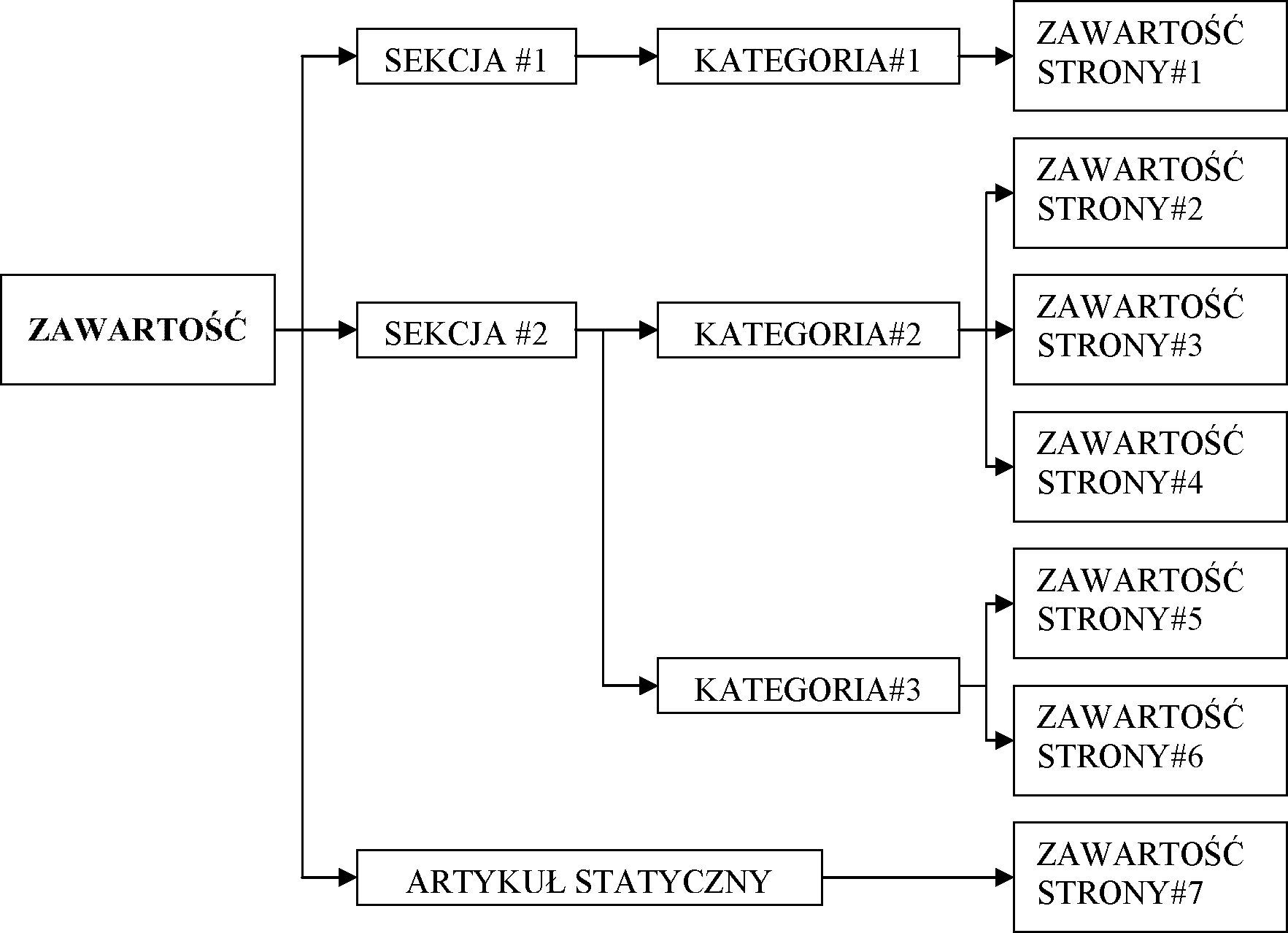
Każda pozycja należy do jakiejś kategorii, a każda kategoria do sekcji lub komponentu.[6] Kategoria nie może istnieć bez sekcji lub poza komponentem, a w sekcji artykułów, a często także w komponencie musi być przynajmniej jedna kategoria. Jedynie w przypadku materiałów statycznych oraz komponentów udostępniających procedury (np. zakupów) nie ma podziału na sekcje i kategorie.
Zawartością w systemach CMS są zarówno sekcje, kategorie, jak i konkretne artykuły, obrazy czy odnośniki. W Joomla! rozróżnia się trzy podstawowe typy zawartości:
- Artykuły dynamiczne – są powiązane z innymi elementami struktury serwisu. Treści te organizowane są w sekcje, a w tych z kolei wyodrębnione są kategorie, którym podporządkowuje się konkretne pozycje zawartości jak artykuły czy wiadomości.
- Artykuły statyczne – to specyficzny rodzaj zawartości, który swoją budową przypomina statyczną stronę opartą na HTML. Stanowi on samodzielny element struktury serwisu. Części składające się na treść strony są tworzone i sortowane na sekcje i kategorie. Elementy te mają charakter dynamiczny i są z reguły wyświetlane chronologicznie. Z artykułami statycznymi jest inaczej; brak powiązań powoduje, że aby udostępnić taki artykuł, należy w sposób „ręczny” umieścić odnośnik do niego w jednym z menu bądź w innym artykule. Jeśli chodzi o uprawnienia edytorskie, to zawartość statyczną mogą tworzyć tylko redaktorzy i administratorzy w panelu administracyjnym serwisu. Artykuły statyczne wykorzystuje się do umieszczania informacji, które nieczęsto ulegają zmianie i stanowią niejako stałe elementy strony, np. regulamin, polityka bezpieczeństwa, dojazd i położenie firmy itp. Treści te można w dowolnej chwili zmieniać, jednak jest to wykonywalne tylko z poziomu administracyjnego.
- Odnośniki lub ich zestawy – to także szczególny rodzaj zawartości. Odnośniki w Joomla! mogą prowadzić do:
o artykułów statycznych i dynamicznych, o kategorii artykułów, o zawartości sekcji artykułów, o dowolnego pliku, strony w Internecie.
Rozszerzenia (komponenty)
Artykuły i materiały statyczne dobrze sprawdzają się w prezentowaniu treści przeznaczonych do przeglądania. Jeśli jednak chcemy zapewnić na witrynie możliwości działania użytkowników, np. dyskusji czy dokonywania zakupów, nie obsłużymy tych potrzeb artykułami. Złożone zadania wymagają bogatszych narzędzi, wygodniejszych w użyciu, dostarczających zaawansowanych możliwości. Tę rolę spełniają w systemach CMS komponenty. To właśnie komponenty czynią je elastycznymi programami dla każdego, który łatwo dostosować do przeróżnych potrzeb – odpowiadają one za możliwość rozwoju systemu. Dla przykładu, komponent rescent news przenosi do szablonu nagłówki najnowszych wiadomości. Inny może pokazywać informacje meteorologiczne z rejonu, w którym mieszka osoba odwiedzająca stronę.
Projektując treści witryny, trzeba rozważyć:
- czy i które z komponentów wykorzystamy,
- czy standardowy zestaw zaspokoi nasze potrzeby,
- czy wystarczą nam oferowane przez wybrane komponenty możliwości,
- jakie komponenty warto j eszcze doinstalować.
- Strony statyczne i dynamiczne
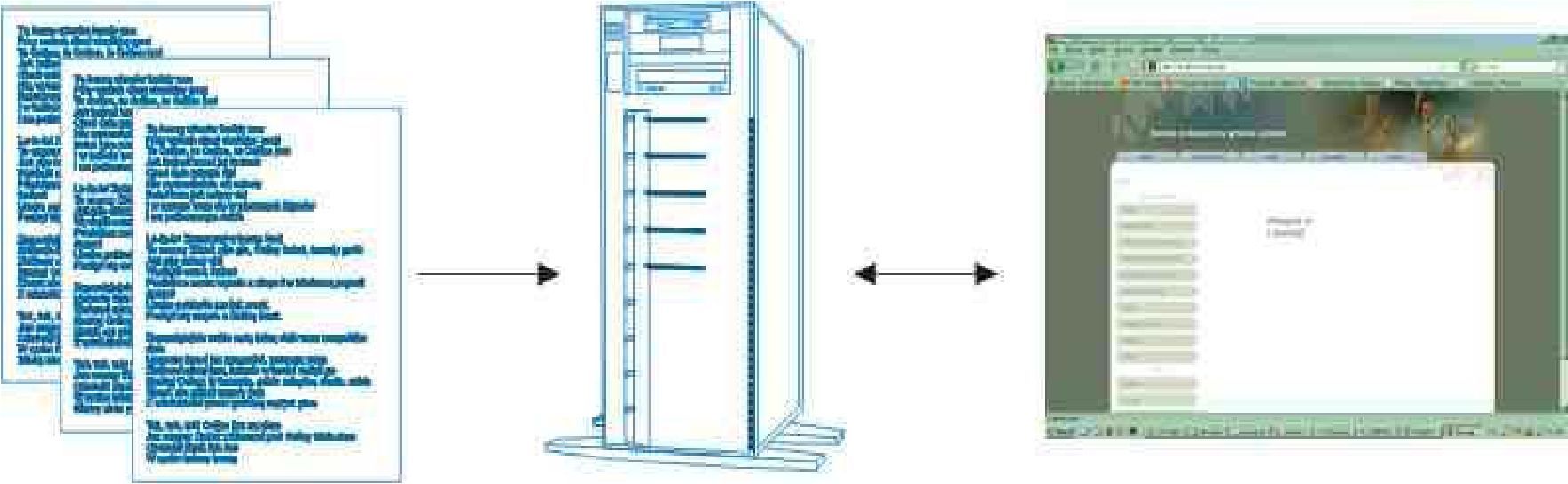
Portal złożony ze stron statycznych jest zbiorem stron HTML i powiązanych plików źródłowych (takich jak obrazki), które są przechowywane na serwerze. Strony statyczne nie są tworzone „w locie”. Zmiany tworzone są poprzez zastąpienie starej strony jej poprawioną wersją na serwerze[7] (rys.3).
Rysunek 3. Schemat budowy statycznej strony internetowej źródło: opracowanie własne, na podstawie [Frankowski P. 2007]
Strony dynamiczne, w przeciwieństwie do stron statycznych, generowane są na bieżąco przez serwer HTTP na podstawie zmiennych i parametrów przekazanych przez przeglądarkę internetową (rys.4). W procesie generowania strony WWW udział bierze współpracujący z serwerem rezydentny moduł lub program zewnętrzny, który interpretuje polecenia zawarte w skrypcie. Wygenerowany w ten sposób dokument w całości opiera się na kodzie HTML.
Funkcjonalność stron dynamicznych ujawnia się dopiero podczas współpracy z serwerami baz danych, gdzie przechowywane są elementy niezbędne do wygenerowania pojedynczej strony WWW – przede wszystkim teksty i grafiki. W dużym uproszczeniu można powiedzieć, że dynamiczna strona to kompozycja dwóch składowych: szablonu decydującego o formatowaniu i zmiennych decydujących o zawartości. Jak wielce pomocna jest technika dynamicznego generowania stron WWW, obrazuje bardzo prosty przykład. Chcąc uruchomić księgarnię internetową oferującą 10 000 książek, a dla każdej książki przygotować dedykowaną stronę WWW, która zawierałaby podstawowe informacje o tej książce – tytuł, autor, wydawca, rok wydania i krótki opis – zmuszeni bylibyśmy do zaprojektowania 10 000 odrębnych plików ze stronami HTML. Przy wykorzystaniu dobrodziejstw dynamicznego generowania stron WWW, ten sam efekt można uzyskać, projektując wyłącznie jedną stronę. Strona taka funkcjonowałaby na zasadzie wspomnianego szablonu, zawierającego stałe elementy formatowania wraz z elementami zmiennymi – informacjami o danej książce – które pobierane byłyby z bazy danych.
Tabela 1. Zestawienie cech zarządzalnej i niezarządzalnej strony
| Cechy |
CMS |
Statyczna strona |
| Miejsceprzechowywania zawartości strony |
Baza danych |
Kod strony |
| Miejsceprzechowywania wyglądu strony (szablonu) |
Wyodrębnione pliki |
Kod strony lub wyodrębnione pliki |
| Tworzenie nowej podstrony |
Nowa podstrona jest tworzona na bazie zdefiniowanego szablonu. Cała nawigacja strony jest automatycznie aktualizowana, bez konieczności ingerowania w jej kod |
Dodanie podstrony wymaga utworzenia nowego pliku, połączenia się z serwerem, wgrania i modyfikacji istniejących plików (odpowiednie odnośniki do istniejących treści) |
| Zmiany na stronie |
Prosta możliwość wprowadzenia zmian w dowolnym momencie. Modyfikacja polegająca na dodaniu lub usunięciu strony nie wymaga wykonywania żadnych zmian graficznych |
Aktualizacja stron wiąże się z ingerencją w kod, co wymaga wiedzy wszystkich użytych technologii. To wymusza interwencję specjalisty, któremu przekazujemy informacje o tym, co chcemy zmienić |
| Szybkość wprowadzania zmian na stronie |
Błyskawiczna. Wystarczy zalogować się do panelu administracyjnego strony, edytować stronę i zapisać zmiany |
Czas od kilku minut do kilku dni, składa się na niego czas przekazania informacji webmasterowi, czas który musi poświęcić na dokonanie poprawek, akceptacja poprawek i wysłanie plików na serwer |
| Narzędzia do edycji strony |
Przeglądarka strony |
Edytor kodu HTML, klient FTP, przeglądarka internetowa |
| Wymagania co do wiedzy technicznej |
Nie jest wymagana specjalistyczna wiedza, wystarczą podstawy edycji tekstu |
Od webmastera wymagana jest specjalistyczna wiedza w zakresieHTML, CSS |
| Model zarządzania |
Rozproszony- różne uprawnienia dla dowolnej liczby osób |
Często scentralizowany- webmaster publikujący wszystkie informacje |
| Koszty utrzymania |
W zależności od skali projektu na cenę mogą składać się opłaty za utrzymania domeny na serwerze, aktualizację systemu CMS, zaprojektowanie CMS (jeśli nie korzystamy z darmowego), jego instalację i skonfigurowanie |
Wysokie, każda aktualizacja wiąże się z wydatkiem na webmastera lub wyspecjalizowaną agencją interaktywną |
| Koszt wdrożenia |
W zależności od wyboru systemu CMS- od darmowego do kilku tysięcy złotych |
Od kilkuset złotych do kilku tysięcy |
| Dodatkowafunkcjonalność |
Szerokie możliwości instalacji dodatkowych modułów |
Wymagana interwencja webmastera, który musi stworzyć nową funkcję |
| Stworzenie nowej wersji językowej strony |
Bardzo uproszczone, dodajemy kolejne strony |
Trudne, wymagana ingerencja webmastera w nawigację strony |
| Zapleczetechniczne |
Konto WWW z obsługa PHP i bazą danych |
Dowolne konto WWW |
| Szybkośćwyświetlania |
Mniejsza od wyświetlania samego kodu HTML, w głównej mierze zależne od parametrów bazy danych |
Duża szybkość wyświetlania |
| Funkcjonalność np.dodanie wyszukiwania wewnątrz strony |
Informacje zachowane w bazie danych, dzięki temu mamy szybki dostęp do informacji |
Możliwe, wymaga jednak tworzenie odpowiednich skryptów |
| Bezpieczeństwodanych |
Z charakteru budowy strony wynika, że cała strona jest przechowywana w dwóch miejscach: lokalnie oraz na serwerze. W razie awarii wystarczy ponownie skopiować pliki na serwer. System jest narażony na ataki hackerów, którzy mają otwarty dostęp do kodu i mogą wyszukiwać w nim błędy |
Wymagane jest robienie kopii zapasowych |
Źródło: opracowanie własne, na podstawie [Rosenfeld L., Morville P. 2003]
Wykorzystanie systemu CMS ma sens, jeśli tworzony przez nas projekt składa się z wielu stron i w założeniu będzie ich systematycznie przybywać, jego treść będzie często ulegać zmianie, równocześnie przy zachowaniu jednolitego wyglądu. Z powyższego zestawienia (tab.1) wynika, iż najważniejszą zaletą systemów CMS jest prostota obsługi, dzięki której od użytkowników wymaga się tylko znajomości podstawowych możliwości popularnych aplikacji biurowych.
Zaletą jest jej możliwość szybkiego i precyzyjnego wprowadzania zmian przez wiele osób oraz obniżenie kosztów administracji strony internetowej. Za wadę należy uznać nieznacznie wolniejsze wyświetlanie stron oraz możliwe ataki na bazę danych. Także graficzny wygląd strony jest narzucony, a jego modyfikacja niesie ze sobą dodatkowe koszty.
[1] Frankowski P., „CMS. Jak szybko i łatwo stworzyć stronę WWW i zarządzać nią.”, Helion, Gliwice 2007
[2] Joomla! Templates [templatka.pl]
[3] HTML (ang. HyperTextMarkup Language) – dominujący język wykorzystywany do tworzenia stron internetowych..
[4] Kaskadowe arkusze stylów (ang. Cascading Style Sheets) to język służący do opisu formy prezentacji (wyświetlania) stron WWW.
[5] Rosenfeld L., Morville P., „Architektura informacji”, Helion, Gliwice 2003
[6] Howil W., „CMS. Praktyczne projekty”, Helion, Gliwice 2007
[7] Linderman M., Fried J., “Przyjazne witryny WWW”, Helion, Gliwice 2005