
W połączeniu typu ABR do kontroli ruchu i przeciążenia używane są następujące parametry:
- PCR (Peak Cell Ratio) –określa maksymalne pasmo przepustowe podczas transmisji komórek w danym połączeniu;
- MCR (Minimum Cell Rate) –określa minimalne pasmo przepustowe podczas transmisji komórek w danym połączeniu;
- ICR (Initial Cell Rate) –określa początkową prędkość transmisji, którą źródło ustawia po połączeniu lub określonym czasie bez aktywności;
- RIF (Rate Increase Factor) lub AIR(Additive Increase Rate) –współczynnik określający maksymalną wielkość jednorazowego zwiększenia pasma przepustowego podczas transmisji komórek;
- Nrm -określa liczbę komórek danych, które źródło może wysłać pomiędzy transmisją komórki zarządzającej RM (Resource Management Cell);
- Mrm -kontroluje przydział pasma pomiędzy komórkami RM a komórkami z danymi;
- RDF (Rate Decrease Factor) – współczynnik zmniejszenia pasma przepustowego podczas transmisji komórek w sytuacji przeciążenia;
- ACR (Allowed Cell Rate) –określa pasmo przepustowe powyżej którego źródło nie może nadawać;
- CRM (Xrm) –określa maksymalną ilość komórek RM, które mogą być wysłane bez otrzymania komórki potwierdzającej RM.
- ADTF (ACR Decrase Time Factor) –określa czas od nadanie ostatniej komórki RM po którym nadawca musi zredukować prędkość do ICR;
- Trm –określa czas pomiędzy kolejnymi wysyłanymi komórkami RM
- RTT (Round Trip Time) –czas propagacji komórki od źródła do odbiorcy i z powrotem.
- CDF (Cutoff Decrease Factor) XDF (Xrm Decrease Factor) –współczynniki redukcji dozwolonego pasma przepustowego ACR, używany z CRM
Komórka zarządzająca RM (Resource Management Cell) używana jest w ruchu ABR i przenosi informacje sterujące zwierające m.in. aktualną prędkość transmisji, informacje o przeciążeniu. Komórka ta jest generowana przez urządzenie nadające dane (źródło danych) do urządzenia odbiorczego (odbiorcy), urządzenie odbiorcze pod odebraniu komórki RM powinno odesłać ją do nadawcy. W zależności od algorytmu kontroli przeciążenia i ruchu komórka ta może być także zmieniana lub wygenerowana przez urządzenie pośrednie: przełącznik.
Tabela 2 przedstawia dokładną strukturę komórki RM. Opis poszczególny pól komórki RM:
- Header –Pięć pierwszych bajtów jest standardowym nagłówkiem komórki ATM z ustawionym dla VPC: PTI=110 i VCI=6 oraz dla VCC: PTI=110
- ID –Protocol ID Identyfikator protokółu. Dla usługi typu ABR wartość jest równa zawsze 1.
- DIR-Direction. Kierunek komórki RM w odniesieniu do transmitowanych danych. Żródło ustawia DIR=0 a powracająca komórka RM ma ustawione DIR=1. Wartość ta może być tylko zmieniona przez element sieci, który zmienia kierunek komórki RM.
- BN –Backwards Explicit Congestion Notification – BECN. Źródło ustawia wartość BN=0. Sieć lub przeznaczenie może wygenerować BECN ustawiająć BN=1, wskazując, że komórka RM nie jest wygenerowana przez źródło.
- CI –Congestion Indication Wartość CI=1 wskazuje na wystąpienie przeciążenia, wartość CI=0 w każdym innym przypadku. Element sieciowy (np. przełącznik) może wysłać komórkę RM do źródło ruchu z ustawionym CI=1, oznaczającą wystąpienie przeciążenia, spowoduje to zmniejszenie wartości ACR przez źródło ruchu.
- NI –No Increase NI=1 powiadamia źródło ruchu, aby nie zwiększało wartość ACR. Parametr ten używany jest zwykle, kiedy przełącznik jest bliski wystąpienia przeciążenia.
- RA –Request/ Acknowledge Parametr nie jest używany w ruchu typu ABR.
- ER –Explicit Cell Rate Wartość używana, do ustawienia parametru ACR źródła ruchu.
- CCR –Current Cell Rate Parametr ten ustawiany jest przez źródło w chwili generowania komórki RM i wynosi aktualną wartość ACR.
- MCR-Minimum Cell Rate
- QL-Queue Length Parametr nie jest używany w ruchu typu ABR.
- SN–Sequence Number Parametr nie jest używany w ruchu typu ABR.
- CRC-10–CRC-10 Parametr CRC jest standardową sumą kontrolną generowaną dla wszystkich komórek ATM.
ATM Forum zdefiniował ogólne zasady dla ruchu typu ABR.
Komórki sterujące RM dla ruchu ABR powinny być generowane z CLP=0, jednak w niektórych sytuacjach, przedstawionych poniżej, urządzenie może wygenerować komórki RM z CLP=1. Wszystkie inne komórki wysyłane są z CLP=0. Komórki z CLP=0 nazywane są in-rate RM-cell, a z CLP=1 out-of-rate RM-cell.
Jednym z zastosowań komórek RM typu out-of-rate jest udostępnienie możliwości zwiększenia prędkości dla połączenia z ACR=0. Źródło może użyć komórek out-of-rate, aby próbkować stan sieci i ewentualnie zwiększyć prędkość.
Zasady dla urządzenia nadawczego (źródła):
- Wartość ACR nie powinna nigdy przekroczyć PCR, ani też nie powinna być mniejsza niż MCR. Źródło nie może generować komórek in-rate przekraczając aktualną prędkość ACR. Źródło może zawsze wysyłać komórki in-rate z prędkością równą lub mniejszą niż ACR.
- Przed wysłaniem pierwszych komórek, po zestawieniu połączenia, źródło musi ustawić parametr ACR=ICR. Pierwszą wygenerowaną komórką musi być komórka sterująca RM typu forward
- Po wysłaniu pierwszej komórki (in-rate forward RM), kolejne komórki powinny być wysyłane w następującej kolejności:
a) Następną komórką in-rate będzie forward RM, gdy:
przynajmniej Mrm komórek in-rate zastało wysłanych i upłynął czas Trm
lub
Nrm-1 komórek in-rate zostało wysłanych.
b) Następną komórką in-rate będzie backward RM, jeżeli warunek 3.A nie został spełniony, komórka backward RM czeka na wysłanie, jak również:
nie została wysłana komórka backward RM od czasu wysłania ostatniej komórki forward RM.
lub nie ma żadnych komórek z danymi do wysłania
c) Następną komórką in-rate będzie komórka z danymi, jeżeli oba warunki 3.A i 3.B nie są spełnione, a dane czekają na wysłanie.
- Komórki spełniające założenia 1, 2, 3 powinny mieć ustawiony bit CLP=0
- Przed wysłaniem komórki forward in-rate RM, jeżeli ACR>ICR i czas, który upłynął od wysłania ostatniej komórki forward in-rate RM jest większy niż ADTF, ACR powinna być zmniejszona do ICR.
- Przed wysłaniem komórki forward in-rate RM i po zastosowaniu pkt. 5, jeżeli przynajmniej CRM komórek forward in-rate RM zostało wysłanych od momentu otrzymania komórki backward in-rate RM z ustawionym bitem BN=0, wartość ACR powinna być zredukowana przynajmniej do ACR*CDF, chyba że wartość ta byłaby mniejsza od MCR, wówczas ACR=MCR.
- Po zastosowaniu zasady 5 i 6, wartość ACR powinna być umieszczona w polu CCR wychodzącej komórki forward RM. Następne komórki in-rate powinny być wysyłane z nową ustaloną prędkością.
- Kiedy źródło otrzyma komórkę backward RM z ustawionym parametrem CI=1, to wartość ACR powinna być zredukowana przynajmniej do ACR*RDF, chyba że wartość ta byłaby mniejsza od MCR, wówczas ACR=MCR. Jeżeli backward RM ma ustawione CI=0 i NI=0, to ACR może być zwiększone o wartość nie większą niż RIF*PCR, ale ACR nie może przekroczyć PCR. Jeżeli źródło otrzyma backward RM z NI=1 nie powinno zwiększać wartości ACR.
- Po otrzymaniu backward RM i obliczeniu wartości ACR wg pkt. 8, źródło ustawia wartość ACR jako minimum z wartości ER i wartości ACR wg pkt. 8, ale nie mniejszą niż MCR.
10. Źródło powinno ustawiać wszystkie wartości komórki RM zgodnie z Tabela 2.
11. Komórki forward Rm mogą być wysłane jako out-of-rate. (tzn. z inną prędkością niż ACR, CLP=1) z prędkością nie większą niż TCR.
12. Źródło musi wyzerować EFCI dla wszystkich transmitowanych komórek.
Zasady dla urządzenia odbiorczego:
- Po otrzymaniu komórki, wartość EFCI powinna być zapamiętana.
- Odbiorca powinien zwrócić otrzymaną komórkę forward RM zmieniając: bit DIR z forward na backward, BN=0 a pola CCR, MCR, ER, CI i NI powinny być niezmienione z wyjątkiem:
a) Jeżeli zachowana wartość EFCI jest ustawiona to CI=1, a wartość EFCI powinna być wyzerowana.
b) Urządzenie odbiorcze, będące w stanie „wewnętrznego” przeciążenia, może zredukować wartość ER do prędkości jaką może obsłużyć lub/i ustawić CI=1 i NI=1. Odbiorca powinien również wyzerować QL i SN, zachowując wartości tych pól lub ustawić je zgodnie z I.371.
- Jeżeli odbiorca otrzyma kolejną ramkę forward RM, a inna „odwrócona” komórka RM czeka na transmisje to:
a) Zawartość starej komórki może być nadpisana przez nową komórkę
b) Stara komórka może być wysłana jako out-of-rate lub usunięta.
c) Nowa komórka musi zostać wysłana.
- Niezależnie od wybranego wariantu w pkt. 3, zawartość starszej komórki nie może być wysłana po wysłaniu nowszej komórki.
- Urządzenie odbiorcze może wygenerować komórkę backward RM nie mając odebranej komórki forward RM. Prędkość takiej komórki powinna być ograniczona do 10komórek na sekundę, na połączenie. Odbiorca generując tą komórkę ustawia również CI=1 lub NI=1, BN=1 i kierunek na backward. Pozostałe wartości komórki RM powinny być ustawione zgodnie z Tabela 2.
- Jeżeli odebrana komórka forward RM ma CLP=1, to wygenerowana na jej podstawie komórka backward może być wysłana jako in-rate lub out-of-rate.
„odwrócenie” odnosi się do procesu wygenerowania komórki backward RM jak odpowiedzi na otrzymaną komórkę forward RM
Algorytm kontroli przeciążenia (kontroli przepływu) typu credit-based opiera się na przekazywaniu „kredytów” od odbiorcy do nadawcy. Przykładem takiego algorytmu może być algorytm: „Flow Controlled Virtual Circuit (FCVC).
Każde łącze składa się z dwóch węzłów: nadawcy i odbiorcy, którymi może być przełącznik lub końcowe urządzenie sieci. Każdy węzeł obsługuje oddzielną kolejkę (bufor) dla każdego kanału wirtualnego. Odbiorca monitoruje długość kolejki dla każdego kanału wirtualnego i określa liczbę komórek (kredyt), które mogą być transmitowane przez dany kanał. Nadawca może wysłać tylko tyle komórek na ile pozwala mu przydzielony kredyt. Jeżeli jest aktywny tylko jeden kanał wirtualny na łączu, kredyt musi być na tyle duży, aby całe pasmo przepustowe łącza było wykorzystane przez cały czas, tj.
Kredyt Przepustowość łącza (w komórkach) X czas roundtrip
Omówiona zasada działania była pierwszą wersją algorytmu FCVC, posiadającą jeszcze kilka poważnych wad. Jedną z najpoważniejszych wad było, że, jeżeli kredyt nie dotarł z powodu nieprzewidzianych sytuacji, odbiorca o tym nie wiedział i nie wysyłał nowych kredytów, nadawca nie mógł wysyłać komórek z braku kredytów. Problem ten został rozwiązany poprzez wprowadzenie synchronizacji kredytów między nadawcą a odbiorcą. Zasada działania algorytmu synchronizacji jest następująca: dla każdego kanału wirtualnego nadawca liczy ilość komórek wysłanych a odbiorca ilość komórek odebranych, wartości te są co pewien czas wymieniane pomiędzy nadawcą a odbiorcą. Różnica między ilością komórek wysłanych przez nadawcę a ilością komórek odebranych przez odbiorcę stanowi ilość komórek „zagubionych”. Odbiorca przydziela więc dodatkowe (utracone) kredyty nadawcy.
Algorytm sterowania przeciążenia typu FECN (Forward explicit congestion notification) jest przykładem algorytmu używającego jako sprzężenia zwrotnego, bitu EFCI (explicit forward congestion indication) w nagłówku komórki ATM.
Rysunek 7. Zasada działania algorytmu FECN
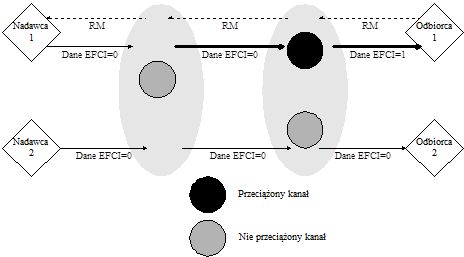
W metodzie tej przełącznik monitoruje długość kolejki w buforze. Jeżeli długość kolejki przekroczy ustalony próg (oznaczający możliwość wystąpienia przeciążenia) przełącznik ustawia bit EFCI dla danych komórek. Urządzenie końcowe, które otrzymało komórki z zaznaczonym bitem EFCI, generuje ramkę kontrolną, informującą o wystąpieniu przeciążenia i wysyła ją do nadawcy. Nadawca używa informacji zawartej w ramce kontrolnej do zmniejszenia lub zwiększenia prędkości transmisji.
Rysunek 7 pokazuje zasadę działania algorytmu FECN. Przełącznik 2 wykrywa przeciążenie (kolejka w buforze przekroczyła dany próg) i ustawia bit EFCI dla wszystkich komórek należących do pierwszego kanału wirtualnego. Odbiorca po dostaniu komórek z bitem EFCI generuje i wysyła komórkę sterującą (RM) informującą nadawcę o fakcie wystąpienia przeciążenia. Nadawca, jeżeli otrzyma komórkę RM, zmniejszy prędkość transmisji danych.
Podobnym algorytmem sterowania przeciążeniem, jest algorytm zwany backward explicit congestion notification -BECN. Algorytm różni się tylko tym, że komórka sterująca RM jest generowana przez urządzenie, które wykryło przeciążenie (przełącznik) a nie tylko przez urządzenie odbiorcze. Oczywistą zaletą metody BECN nad FECN jest szybsza reakcja na wystąpienie przeciążenia. Następną zaletą jest niezależność od systemu końcowego (w algorytmie FECN odbiorca generuje RM), ponieważ urządzenia sieciowe same generują komórki sterujące. Jednak metoda BECN wymaga od bardziej rozbudowanych przełączników, potrafiących nie tylko generować komórki sterujące ale także filtrować informacje o przeciążeniu. Proces filtrowania informacji o przeciążenia jest niezbędny, aby móc zapobiec nadmiernej liczbie generowanych komórek sterujących.
Rysunek 8. Zasada działania algorytmu BECN
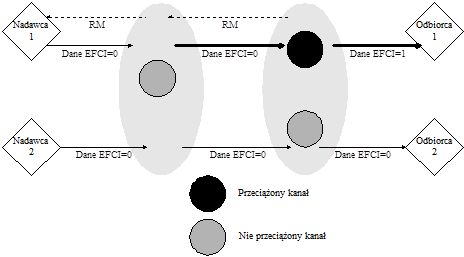
W obydwóch algorytmach FECN i BECN, przełącznik wykrywa przeciążenie, kiedy długość kolejki przekroczy dany próg. Nadawca, jeżeli odebrał komórkę sterującą zmniejsza prędkość transmisji danych. Prędkość ta może być automatycznie zwiększona przez źródło, jeżeli nadawca nie otrzymał komórki sterującej przez z góry określony czas, do prędkości ustalonej podczas ustanawiania połączenia (PCR). Największą wadą obydwu metod jest brak odporność na niektóre sytuacje, np. jeżeli podczas przeciążenia komórka sterująca nie będzie mogła dotrzeć do nadawcy, to nadawca nie wiedząc o wystąpieniu zwiększy swoją prędkość transmisji, co spowoduje jeszcze większe przeciążenie.
W opisanych powyżej algorytmach FECN i BECN, bazujących na ujemnym sprzężeniu zwrotnym (tzn. źródło zmniejszało swoją prędkość po dostaniu komórki sterującej), występował problem zwiększania się przeciążenia na skutek utraty komórek sterujących. W celu usunięcia tej wady zaproponowano algorytm PRCA, bazujący na dodatnim sprzężeniu zwrotnym. W algorytmie tym, źródło zwiększa prędkość transmisji danych tylko wtedy gdy dostanie komórkę sterującą, jeżeli źródło nie dostanie komórki sterującej to samo zmniejsza prędkość. Zmiana prędkości transmisji jest proporcjonalna do aktualnej prędkości danego źródła.
Rysunek 9 Zasada działania algorytmu PRCA
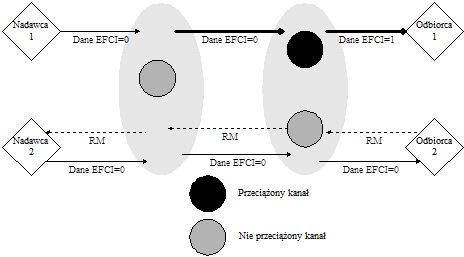
Zasada działania algorytmu jest następująca: Źródło (nadawca) wysyła wszystkie komórki danych z ustawionym bitem EFCI z wyjątkiem pierwszej i N-tej komórki. Parametr N jest ustalany w początkowej fazie łączenia i wielkość jego wpływa na czas reakcji na przeciążenie. Jeżeli odbiorca odbierze komórkę danych z wyzerowanym bitem EFCI i nie samo przeciążone, to generuje i wysyła komórkę sterującą RM. Źródło zwiększa prędkość transmisji, jeżeli tylko otrzyma komórkę RM od odbiorcy. Przełącznik, który wykryje przeciążenie może ustawić bit EFCI lub usunąć komórkę sterującą RM, wysłaną przez odbiorcę. Źródło zaczyna zmniejszać prędkość transmisji od momentu nie dostania komórki RM, aż do chwili gdy sieć przestanie być przeciążona i źródło dostanie komórkę RM.
Algorytm PRCA rozwiązuje problem występujący w algorytmach BECN i FECN, ale zauważono inny problem, tzn. niesprawiedliwy przedział pasma. Jeżeli, mamy sieć zbudowaną z kilku przełączników i poziom przeciążenia jest taki sam na wszystkich przełącznikach, to kanał wirtualny przechodzący przez większą ilość przełączników ma większe prawdopodobieństwo dostania komórki z ustawionym bitem EFCI (wskazującym na przeciążenie) niż kanał wirtualny przechodzący przez mniejszą ilość przełączników. Jeżeli p jest prawdopodobieństwem ustawienie bitu EFCI przy przejściu przez jeden przełącznik(hop), to prawdopodobieństwo ustawienia EFCI dla kanału wirtualnego VC składającego się z n przełączników wynosi 1-(1-p)n lub np. Tak więc „dłuższy” kanał wirtualny ma mniejszą szansę na zwiększenie prędkości transmisji i częściej musi zmniejszać prędkość niż „krótszy” kanał wirtualny. Problem ten nazwano „beat-down problem” . Rysunek 10 przedstawia konfigurację sieci składającą się z 4 przełączników i 4 kanałów wirtualnych. Przeprowadzone symulacje[3] (Rysunek 11) wykazały, że prędkość transmisji dla kanału 4, zastała zredukowana do zbyt małej wielkości w porównaniu do innych kanałów. Wystąpił więc niesprawiedliwy przedział dostępnego pasma.
Omówiony wcześniej algorytm PRCA okazał się zbyt wolny. Sprzężenie zwrotne używane w algorytmie PRCA mówiło tylko o braku wystąpienia przeciążenia i pozwalało na zwiększenie prędkości przez źródło. Ustalanie optymalnej prędkości związane było z koniecznością wysłania kilku komórek zarządzających. Algorytm EPRCA powstał przez połączeni algorytm PRCA i algorytmu typu explicit-rate,(tzn. algorytmu używającego sprzężenia zwrotnego przenoszącego więcej informacji. np. aktualna prędkość, prędkość optymalna). Zasada działania algorytmu jest następująca:
Źródło wysyła wszystkie komórki z danymi, z ustawionym bitem EFCI=0. Komórka zarządzająca RM jest wysyłana co n komórek danych. Komórka RM zawiera aktualną prędkość CCR(current cell rate)), prędkość docelową ER(explicit rate) i bit informujący o przeciążeniu CI (congestion indication). Źródło ustawia wartość ER na swoją maksymalną dozwoloną prędkość PCR(peak cell rate)i ustawia bit CI=0.
Przełącznik oblicza współczynnik fairshare, czyli optymalne pasmo przepustowe dla danego połączenia i jeżeli potrzeba to redukuje wartość ER w powracającej komórce RM do wartości fairshare. Używając ważonej średniej potęgowej obliczamy dozwoloną średnią przepływność bitową MACR (mean allowed cell rate), współczynniki fairshare przyjmuje część wartości obliczonej średniej.
MACR = (1 – a) MACR – aCCR
Fairshare = SW_DPF x MACR
gdzie, a jest współczynnikiem (rzędem) średniej potęgowej, SW_DPF jest mnożnikiem (zwanym współczynnikiem switch down pressure) bliskim, ale poniżej jedności. Sugerowane wartości dla a to 1/16 a dla SW_DPF to 7/8.
Źródło zmniejsza aktualną prędkość nadawania ACR po każdej nadanej komórce:
ACR = ACR x RDF
gdzie, RDF jest współczynnikiem redukcji.
Jeżeli źródło odbierze powrotną komórkę zarządzającą RM (nie mającą ustawionego bitu CI) zwiększa prędkość nadawania:
jeżeli CI = 0 to ACR = min(ACR + AIR, ER, PCR)
gdzie, AIR jest współczynnikiem zwiększenia.
Odbiorca monitoruje także bit EFCI w komórkach danych i jeżeli ostatnio odebrana komórka miała ustawiony ten bit, odbiorca ustawia bit CI w generowanej komórce zarządzającej RM.
Przełącznik oprócz ustawienia prędkości ER może także, jeżeli długość jego kolejki przekroczy ustalony próg ustawić bit CI w powracającej komórce RM.
Target Utilization Band (TUB) jest algorytmem należących do grupy algorytmów zapobiegających stanom przeciążenia. Przedstawiony algorytm utrzymuje stale zajętości pasma na poziomie 85%-90%, nie pozwalając na zbyt dużą transmisję, która spowodowałaby przeciążenie łącza. Zasada działania jest następująca:
Dla każdego przełącznika, definiujemy prędkość wyjściową niewiele poniżej przepustowości łącza wyjściowego ok. 85%-90%. Prędkość wejściowa jest mierzona w określonych, krótkich odcinkach czasu. Liczymy współczynnik wykorzystania pasma (load factor) z.
Algorytm rozróżnia dwie sytuacje:
a) Jeżeli obliczony współczynnik z jest daleki od 1 (tzn. prędkość wyjściowa jest mniejsza lub większa o 10% od zadeklarowanej prędkości wyjściowej), znaczy to, że przełącznik jest albo silnie przeciążony albo jego wykorzystanie jest niewielkie. Wszystkie kanały wirtualne przechodzące przez dany przełącznik są wówczas zmuszone do zmiany swojej prędkości, dzieląc prędkość przez współczynnik z.
b) Jeżeli parametr z jest bliski 1, pomiędzy 1-delta i 1+delta dla małej delty, przełącznik generuje różne sprzężenie zwrotne dla każdego kanału wirtualnego, przeładowanego lub nie wykorzystanego.
Źródła, które transmitują dane z większą prędkością niż obliczony współczynnik fairshare muszą zmniejszyć swoją prędkość dzieląc ją przez z/(1-delta). Źródła, które transmitują dane ze zbyt małą prędkością, zwiększają ją dzieląc ją przez z/(1+delta).
Algorytm ERICA stara się maksymalnie wykorzystać dostępne pasmo łącza, zachowując jednocześnie sprawiedliwy przedział pasma. Algorytm pozwala źródłom, transmitującym z prędkością równą lub większą z obliczonym współczynnikiem fairshare, na zwiększenie prędkości transmisji w kanale wirtualnym, jeżeli dany kanał wymaga większej przepustowości a łącze nie jest w pełni wykorzystane.
Dla algorytmu tego, definiujemy prędkość wyjściową większą niż dla poprzednio omówionego algorytm, 90-95% przepustowości łącza. Przełącznik oblicza współczynnik fairshare:
Prędkość, którą dodatkowa źródło może użyć:
Przełącznik ustawia prędkość źródła na prędkość największą (Fairshare lub Vcshare)
Informacje wykorzystywane przy obliczeniach w algorytmie, dostarczane są komórkami RM z urządzenia nadawczego i odbiorczego.
Zaletą tego algorytmu jest prostota i łatwość przeprowadzanych obliczeń.
Po raz pierwszy algorytm MIT został zaproponowany przez Anna Charny z Massachusetts Institute of Technology (MIT).
Algorytm ten do obliczenia współczynnika fairshare używa procedury iteracyjnej. Najpierw, współczynnik fairshare obliczany jest poprzez podzielenie dostępnego pasma przepustowego przez ilość aktywnych kanałów wirtualnych. Wszystkie kanały, które transmitują dane z prędkością poniżej obliczonego współczynnika fairshare, są zwane „underloading VC”. Jeżeli liczba kanałów „underloading VC” zwiększa się z iteracją, współczynnik fairshare jest obliczany według wzoru:
Procedura ta powtarzana jest dopóki nie osiągnie się stanu stabilnego, gdzie liczba „underloading VC” i współczynnik fairshare nie będzie się zmieniał. Anna Charny pokazała w swojej pracy, że zwykle dwie iteracje wystarczą do osiągnięcia zadawalającego rezultatu. Jednak mogą wystąpić sytuacje, dla których obliczenie współczynnika fairshare składać się będzie z n operacji, gdzie n jest liczbą kanałów wirtualnych. Dla przełączników ATM, które obsługują tysiące kanałów wirtualnych, liczba obliczeń koniecznych do wykonania stanie się bardzo duża i nie może być wykonana na dostępnym dzisiaj sprzęcie.