Pozycjonowaniem stron nazywamy wszelkie działania mające na celu umieszczenie strony www na jak najwyższej pozycji w wynikach wyszukiwania dla konkretnych fraz.
Pozycjonowanie naturalne
Najprostsza z form pozycjonowania, jednak sprawdzająca się w nielicznych przypadkach. Charakteryzuje się tym, że osoba pozycjonująca liczy na zdobycie przez stronę www popularności bez żadnych działań. Co za tym idzie ludzie będą dzielić się między sobą informacją o takiej witrynie. Internauci informując się nawzajem o obecności takiej strony w Internecie zostawiają wpisy na forach, blogach, grupach dyskusyjnych, prywatnych stronach www, itd. wraz z odnośnikiem do strony pozycjonowanej.
W praktyce pozycjonowanie naturalne jest rzadko używane. Może sprawdzić się tylko dla stron internetowych, które okazują się „strzałem w dziesiątkę” i stają się bardzo popularne. Strony firm czy instytucji, które pozycjonowanie traktują jako formę reklamy nigdy nie będą dla Internautów tak atrakcyjne, aby mogły zostać wypozycjonowane w sposób naturalny.
Pozycjonowanie przez optymalizację
Ta forma pozycjonowania polega na wykorzystaniu wiedzy dotyczącej optymalizacji stron internetowych pod kątem wyszukiwarek. Szerzej można przeczytać w rozdziale „Optymalizacja stron internetowych pod kątem wyszukiwarek” powyższej pracy. Im lepiej strona www jest zoptymalizowana tym wyszukiwarka traktuje ją jako ważniejszą, a co za tym idzie wyświetla ją na wyższych pozycjach w wynikach wyszukiwania.
Bez wątpienia pozycjonowanie przez optymalizację w przypadkach, gdzie fraza nie jest zbyt konkurencyjna okazuje się wystarczającą formą dotarcia na najwyższe pozycję wyników. Jednak kompletnie nie sprawdza się dla bardziej konkurencyjnych słów kluczowych.
Pozycjonowanie nieetyczne
Bardzo ciężko zdefiniować jest granicę między metodami etycznymi, a nieetycznymi. Jest ona bardzo cienka i płynna. Wiele wyszukiwarek w swych regulaminach mówi, że każda ingerencja w proces indeksacji strony internetowej jest działaniem zabronionym. A przecież każde pozycjonowanie za wyjątkiem pozycjonowania naturalnego jest właśnie takim działaniem.
Poniżej przedstawione zostaną najpopularniejsze sztuczki, które są powszechnie uznawane za nieetyczne. Do metod nieetycznych można również zaliczyć spamowanie wyszukiwarek, które zostanie przedstawione w podrozdziale „Spam w wyszukiwarkach i jego klasyfikacja”.
Ukryty tekst
Najbardziej popularnym i najczęściej stosowanym sposobem nieetycznego pozycjonowania jest właśnie stosowanie ukrytego tekstu. Ukryty tekst jest de facto widoczny tylko dla robota wyszukiwarki, chyba że użytkownik zajrzy w kod źródłowy strony. Ukryty tekst najczęściej jest nasycony słowami kluczowymi, na które jest pozycjonowana dana witryna.
Tekst może zostać ukrywany na wiele sposobów. Do najprostszych należy: stosowanie takiego samego koloru czcionki jak kolor tła strony, zminimalizowanie wielkości czcionki do 1 piksela, wypełnienie tekstem daleko od końca tekstu właściwego na stronie (zastosowanie znaków końca linii).
Komentarze w kodzie HTML
Kolejną metodą nieetycznego pozycjonowania jest zastosowanie komentarzy w kodzie HTML. Komentarze te zawierają nie opis kodu, czyli to do czego zostały stworzone, a sztuczny tekst, który ma pomóc w pozycjonowaniu strony w wyszukiwarkach. Najczęściej naszpikowany jest on słowami kluczowymi pod jakie pozycjonowana jest strona.
Ukryta warstwa
Ukryta warstwa nie jest widoczna dla użytkownika strony internetowej. Nie zawsze w kodzie źródłowym strony jest łatwa do wychwycenia. W takiej warstwie można zmieścić dowolną ilość odpowiednio przygotowanego tekstu, który ma zapewnić lepszą pozycję w wynikach wyszukiwania. Warstwy można ukrywać na wiele sposobów, jednak zawsze trzeba użyć do tego arkuszy styli CSS.
Duplikowanie treści
Duplikowanie treści to nic innego jak umieszczenie na witrynie podstron o tej samej lub bardzo zbliżonej treści. Strona internetowa posiadająca więcej podstron postrzegana jest przez wyszukiwarkę jako atrakcyjniejsza merytorycznie. Jednak duplikowanie treści w chwili obecnej jest już łatwo rozpoznawalne przez wyszukiwarki.
Stosowanie nieetycznych metod pozycjonowania w łatwy sposób może doprowadzić do efektu odwrotnego niż zakładany. Na przykład umieszczenia strony na dalekiej pozycji w wynikach wyszukiwania lub całkowitej jej usunięcia z tych wyników. O wszystkich zagrożeniach wynikających z niewłaściwego pozycjonowania strony internetowej będzie mowa w dalszej części pracy na przykładzie wyszukiwarki google.pl.
Pozycjonowanie właściwe
Zajmijmy się pozycjonowaniem, które powinno być zawsze stosowane przez profesjonalistów. Dzięki pozycjonowaniu właściwemu jesteśmy w stanie praktycznie każdą stronę na prawie dowolne słowo kluczowe umieścić bardzo wysoko w wynikach wyszukiwania.
Jak to zrobić?
Od razu nasuwa się odpowiedź: zastosować wszystkie powyższe metody. Jest w tym wiele racji jednak nie jest to takie proste. Jak już wiadomo wyszukiwarki internetowe uważają pozycjonowanie stron jako coś złego, bronią się przed tym. W takim razie pozycjonując stronę internetową musimy się starać oszukać algorytm wyszukiwarki odpowiadający za umieszczanie stron na odpowiednich pozycjach. Skoro staramy się oszukać algorytm nie stosujmy metod nieetycznych, z kilku względów. Po pierwsze bywają łatwo identyfikowalne przez wyszukiwarki i pozycjonowanie może przynieść odwrotny skutek. Po drugie każdy szanujący się pozycjoner nie używa metod nieetycznych z samej definicji tego słowa. Aby strona było odpowiednio pozycjonowana należy na samym początku zadbać o jej optymalizację pod względem wyszukiwarek internetowych. Jest to bardzo ważny element pozycjonowania właściwego i nie należy o nim zapominać. Kolejną ważną rzeczą jest zapewnienie stronie odpowiedniej ilości linków do niej. Linki powinny być odpowiednio dobierane. Nie należy przesadzać z ich ilością, ważna też jest jakość odnośników. Jak pozyskiwać linki będzie mowa w dalszej części tego rozdziału. Odnośniki prowadzące do pozycjonowane strony muszą być dobierane w odpowiedniej ilości i w odpowiednim czasie. Nie może zdarzyć się sytuacja, aby do naszej strony w ciągu jednego dnia robot wyszukiwarki znalazł np. 1000 linków. Tak więc przyrost linków należy stale monitorować. Istotną rzeczą jest to, aby odnośnik do strony był stały nie tymczasowy, czyli np. przydzielony na dwa miesiące.
Poniższe wykresy przedstawiają dobry i zły przyrost linków w czasie do strony pozycjonowanej.
Rysunek 3 Przykład złego linkowania w czasie
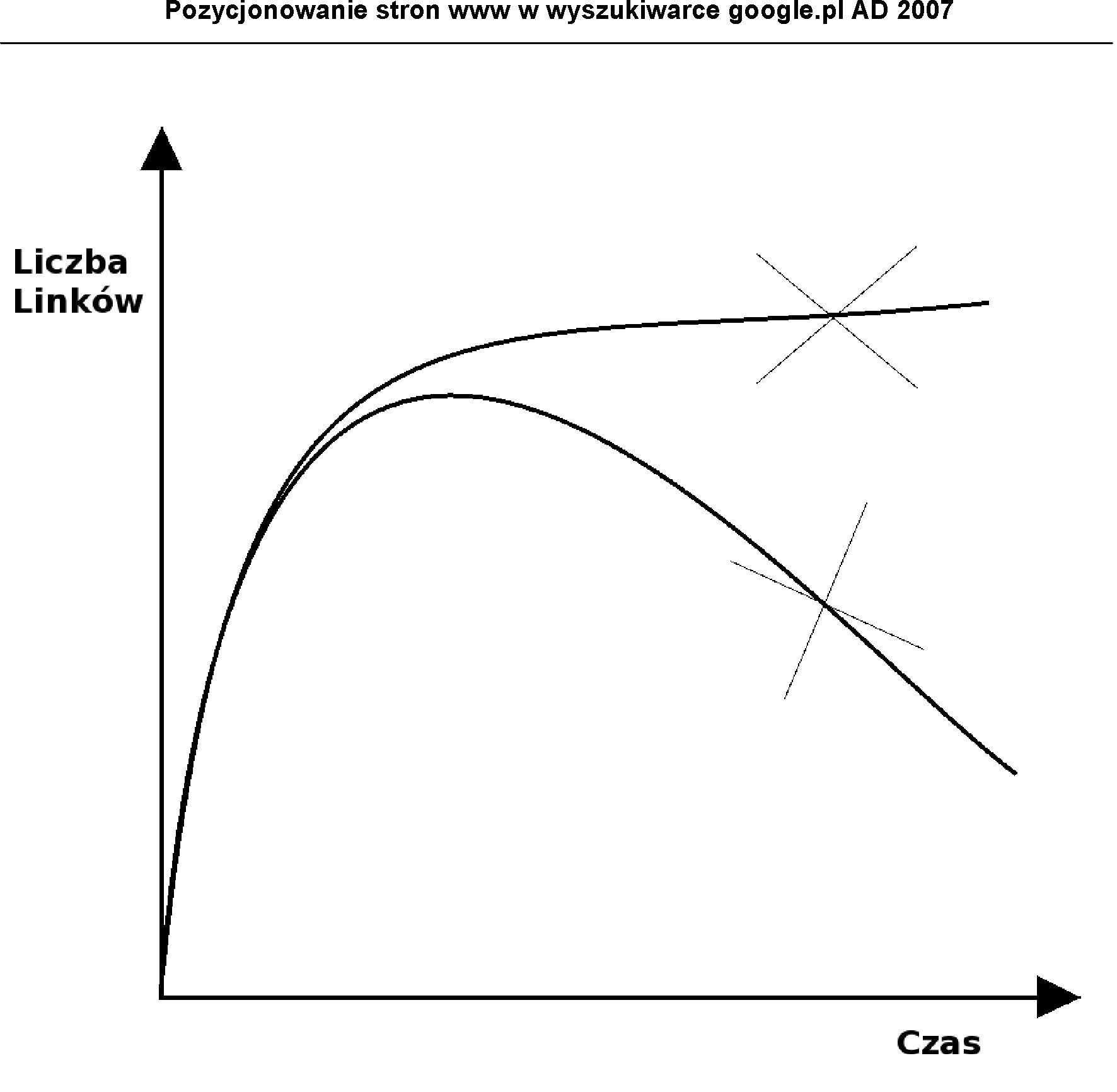 Źródło: Opracowanie własne
Źródło: Opracowanie własne
Rysunek 4 Przykład prawidłowego linkowania w czasie
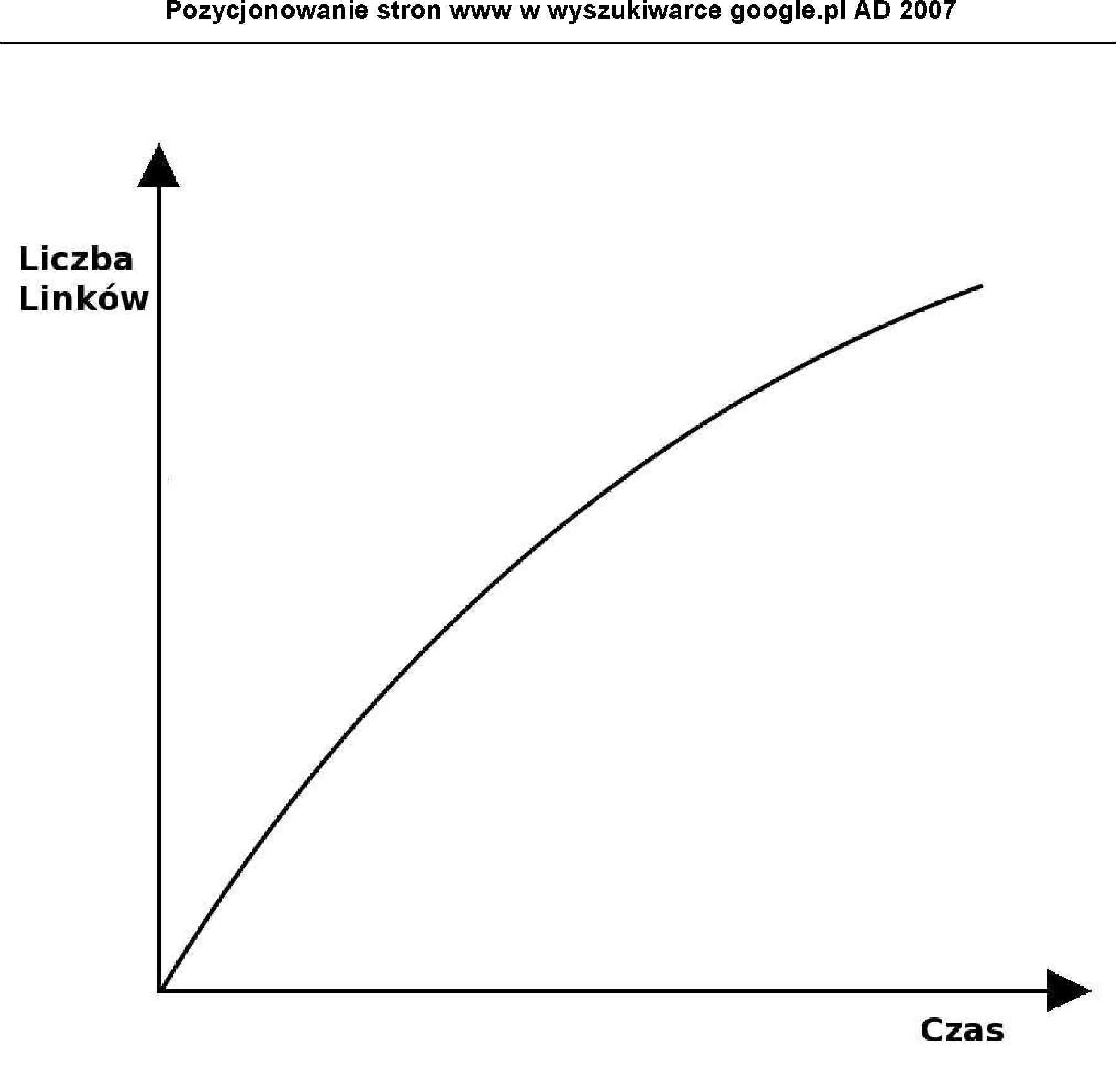 Źródło: Opracowanie własne
Źródło: Opracowanie własne
Podsumowując możemy wyróżnić cztery główne sposoby pozycjonowania stron internetowych w wyszukiwarkach. Wszystkie te metody różnią się od siebie z sposób zdecydowany. W rozdziale „Porównanie metod pozycjonowania stron www w wyszukiwarce google.pl” zajmiemy się odpowiedzią na pytanie, która metoda pozycjonowania jest najkorzystniejsza i jakie ewentualne zagrożenia niesie.